你是否想過:
如果不知道問題的答案,就跟著筆者一起閱讀作業系統追尋問題的答案吧!
參考 Operating System Concepts - 9th 一書對 File system 的描述:
檔案系統負責了邏輯塊與物理塊之間的轉換、管理剩餘空間並分配記憶體。採用分層的設計可以降低檔案系統的複雜度,實務上,不同檔案系統的分層都會有些微的差異。
作業系統可能支援一個或多個以上的檔案系統,常見的檔案系統有: FAT 、 exFAT 、 NTFS 、 HFS 、 HFS+ 、 ext2 、 ext3 、 ext4 、 ODS-5 、 btrfs 、 XFS 、 UFS 、 ZFS 等。
這裡的作業系統包含常見的作業系統 (Mac OS, Windows, Android, UNIX, Linux...)以及一些運作在特殊裝置的作業系統 (印表機、隨身聽等等)。
根據恐龍書,我們可以得知檔案目錄的實作有兩種方法,分別是:
| File name | Address (First block) |
|---|---|
| index.js | 1 |
| readme.md | 20 |
Hash table
因為 Hash table 的特性,如果以 Hash table 實作檔案目錄,可以大幅優化檔案的查詢速度。不過,也因為該資料結構的缺點,會有碰撞和增加空間使用的問題。
檔案目錄紀錄了檔案 (First block) 的物理位址,不過一個檔案通常是由多個 block 組成。因為這樣,檔案系統也設計了 Block 的分配方法:
| File | Start | Length |
|---|---|---|
| readme | 0 | 2 |
| main.c | 2 | 3 |
| index.js | 5 | 3 |
根據上面的配置方法,檔案在儲存裝置的分配會像是:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|
| readme | readme | main.c | main.c | main.c | index.js | index.js | index.js |
Linked allocation
Contiguous allocation 的優點顯而易見: 因為是連續記憶體,所以讀檔速度極快。 But!!! Contiguous allocation 也有非常明顯的缺陷,以拉麵的故事為例: 筆者之前在中山區某知名拉麵店門口排隊,店內只有約 10 個位置排在吧檯,看起來就像是一條連續記憶體。筆者那天跟其餘兩位朋友排隊,當時店內有 3 個空位:
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|
| X | 空 | X | X | 空 | X | X | 空 | X | X |
因為 Contiguous allocation 的特性,我們必須坐在一塊,這樣就出現了一個問題: 明明有足夠的位子,我們卻無法入坐享受熱騰騰的拉麵,只能眼睜睜看著孤獨的拉麵獵人比我們先入坐 : )
為了阻止這樣的悲劇,Linked allocation 出現了!
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|
| X | 朋朋1 | X | X | 朋朋2 | X | X | 朋朋3 | X | X |
朋朋 1 知道 朋朋 2 坐在第五個位置,朋朋 2 知道朋朋 3 坐在第八個位置,而檔案目錄會記錄朋朋 1 的位置。
如果看到這裡你還沒離開,恭喜你已經了解 FAT32 的設計了 \ (^ _ ^) /
Indexed allocation
Linked allocation 雖然讓我們能順利吃到拉麵,但同行的朋友需要紀錄其他人的位置,應該還有更聰明的辦法吧!當眾人陷入沉思時,資料科學家說話了:
邊吃拉麵一邊群組通話不就好了?
對阿,開個群聊不就解決了嗎?讓我們來看看 Indexed allocation 的設計:
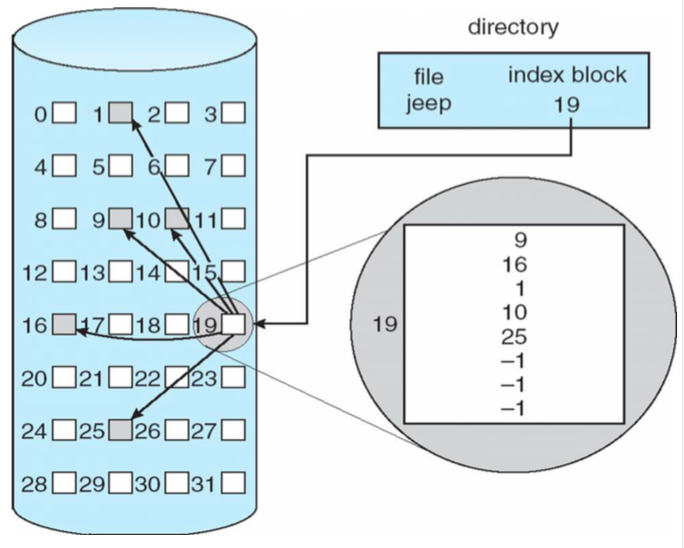
檔案目錄紀錄了檔案的 Index block,而存放在磁碟中的 Index block 就像是群組聊天室,讓同行的拉麵朋朋都可以參與視訊。
關於磁碟重組
當店內同行的客人分別坐在不同的地方時,機靈的拉麵店店員可以請客人挪動位子,讓同行的人盡可能的坐在一塊。
當資料被寫在一起,磁碟的讀寫頭不需要不停的移動,一圈就能讀完所需資料,因此,磁碟重組(重新分配坐位)可以大幅的提升磁碟的讀寫速度。

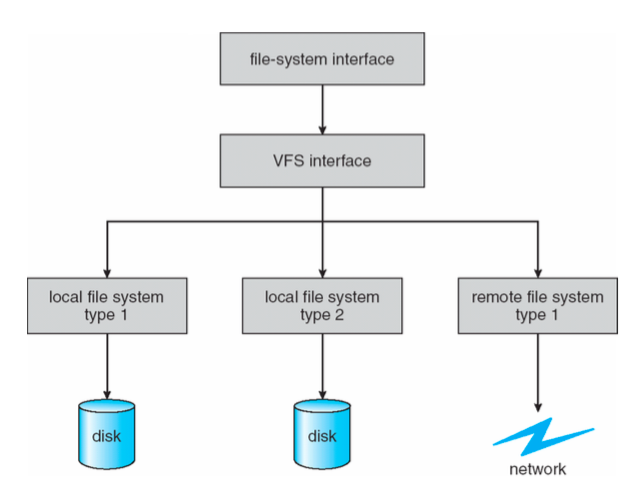
上圖為 Linux 的檔案系統架構。
Virtual file system 使用物件導向開發,它讓使用者 / 開發者在操作檔案時不需要了解各個檔案系統的實作,只需要呼叫 System call 就可以達到操作檔案的目的。
換言之,有了 Virtual file system,管你拉麵店放圓桌還是吧台,我通通都能處理!
不只如此,有了 Virtual file system 讓作業系統可以存取多個不同檔案系統的裝置:
以下內容取自叫人頭昏眼花的 stdio library 一文。
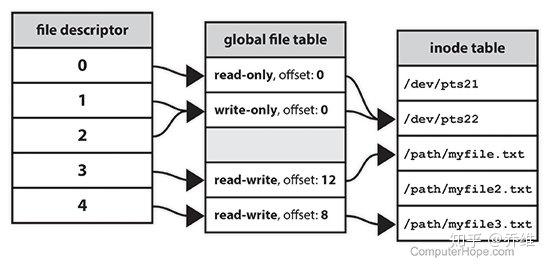
在 Unix 或是 Unix-like 中,作業系統抽象了一層資料結構用來存取 File, input / output 資源,該資料結構稱為 File descriptor。並且,File descriptor 是屬於 POSIX API 的一部份,在符合 POSIX 的作業系統上,每一個 Process (除了守護程序) 都應該具備至少三個 File descriptor,分別是:
| Integer value (>=0) | Name | <stdio.h> file stream |
|---|---|---|
| 0 | Standard input | stdin |
| 1 | Standard output | stdout |
| 2 | Standard error | stderr |
inode 的設計最早可以追朔到第一版的 UNIX 作業系統,至今,大部分的 UNIX-like 都採用類似的檔案系統設計,就讓我們一起來看看什麼是 inode 吧!
inode (index node) 是指在許多「類 Unix 檔案系統」中的一種資料結構,用於描述檔案系統物件(包括檔案、目錄、裝置檔案、 socket 、管道等)。每個 inode 儲存了檔案系統物件資料的屬性和磁碟塊位置。檔案系統物件屬性包含了各種元資料,如:最後修改時間、使用者群組 (owner) 和權限資料。
metadata (元資料) 這個名詞對多數開發者都不算陌生,就像是原子操作這個名詞一樣,我們無法立刻了解元資料到底是什麼資料。
實際上,Metadata 就是一個用來描述資料的資料,舉例來說,在 *.html 檔案中,我們可以在 <head> 裡面找到許多 metadata 的 Target,這些標籤都是用來描述這個 *.html 檔案。
在了解 file descriptor 後,我們可以在上圖看到每個 file descriptor 都會指向一個全域的檔案表,檔案表則會指向 inode table。
inode table 其實就是一個存放 inode 的陣列,在檔案系統中,他會記錄所有的檔案 (inode)。
xv6 是一個研究/教學用途的小型作業系統,他對於檔案系統有完整的實作。
在 xv6 的檔案系統中,inode 有兩種意義:
struct dinode {
short type; // File type
short major; // Major device number (T_DEVICE only)
short minor; // Minor device number (T_DEVICE only)
short nlink; // Number of links to inode in file system
uint size; // Size of file (bytes)
uint addrs[NDIRECT+1]; // Data block addresses
};
dinode 為實際存放在磁碟中的 inode,我們可以透過上方的程式碼了解 dinode 結構中每個屬性的定義:
紀錄在 Memory 上的 inode,是紀錄在磁碟中的 inode 的副本。此外還記錄了 Kernel 的相關資訊:
struct inode {
uint dev; // Device number
uint inum; // Inode number
int ref; // Reference count
struct sleeplock lock; // protects everything below here
int valid; // inode has been read from disk?
short type; // copy of disk inode
short major;
short minor;
short nlink;
uint size;
uint addrs[NDIRECT+1];
};
我們在撰寫 C 語言並用其讀取檔案時,會出現與下方程式類似的用法:
fp = fopen(file_name, "r");
while((ch = fgetc(fp)) != EOF)
實際上,我們可以把讀檔拆成好幾個步驟:
fopen
BTW: OS 透過 Driver 讀取 HDD 的內容時,還需要考慮:
- 排程演算法
第一次執行 dir 指令或是開檔案會比較慢,因為要從 File Control Block 查找資料。之後在開就會變快了(因為已經被 Cache 了)。
通常來說,第一個 Block 一定是 Root。
在這個過程中,一共做了 2 次記憶體存取:
之前聽到電子系上的前輩說什麼生活電磁學(?),好啊!要互相傷害是不是?那我也來搞一個拉麵檔案系統阿! (讀書讀到頭殼壞掉)。
本篇文章用愉快的步調學習枯燥乏味的檔案系統,希望能夠引起讀者對作業系統的興趣。

